Stop Prompting. Start Looping.
Infra behind self improving loops

On June 2, 2026, Boris Cherny — the Anthropic engineer who created Claude Code — went on the Acquired Unplugged podcast and said this:
“I don’t prompt Claude anymore. I have loops running that prompt Claude and figuring out what to do. My job is to write loops.”
Six days later, Peter Steinberger — the developer behind OpenClaw — posted this to X:
“Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore. You should be designing loops that prompt your agents.”
The tweet got 6.5 million views. The next day, Google’s Addy Osmani published an essay giving the idea a name: loop engineering. Cherny repeated the claim two weeks later on stage at Meta’s @Scale conference, adding a line worth sitting with: “As big as the step from source code to agents was, loops are just as important and as big a step.”
That is the real shift: the human stops writing every instruction and starts designing what deserves to run, what evidence counts, and when the machine must stop.
Not because “loop” is a new word, but because reliability, cost, and verification have become the bottleneck. If agents are going to act without a human typing every step, the hard question is not whether they can do the work once. It is whether they can repeat it safely, cheaply, and with evidence.
What a loop actually is
A prompt is a request. A loop is a system. It has a trigger, gathers context, takes action, checks the result, and either stops or runs again. The human no longer has to notice every task and type every instruction.
Loop engineering is the work of designing that system: what starts it, what context it sees, what tools it can touch, what evidence counts as success, and what forces it to stop.

The important point for investors: once a loop starts running unattended, the valuable product is no longer just the model. It is the infrastructure around the model.
How loops work, and the research behind them
The mechanism is not new. The market timing is. What changed is that four years of agent research have converged into a product pattern people can actually run: give the model tools, give it memory, let it act, verify what happened, and repeat until a stop condition fires.
The useful compression is five primitives. ReAct gave us the action-observation loop. Toolformer and function-calling APIs made tool use feel native. Reflexion and Self-Refine added critique-and-retry. Generative Agents and Voyager showed why memory and reusable skills matter. SWE-bench, τ-bench, and AI Agents That Matter forced the field to measure reliability and cost, not just impressive demos.
So the research story is simple: act, observe, remember, verify, repeat. The commercial story is sharper: every one of those verbs needs infrastructure.
The infrastructure loops need
Once a loop can run without a human sitting between every step, the product stops being a prompt interface and starts looking like an operating system for work. The stack has seven layers: triggers, context, tool access, execution, verification, observability, and governance.
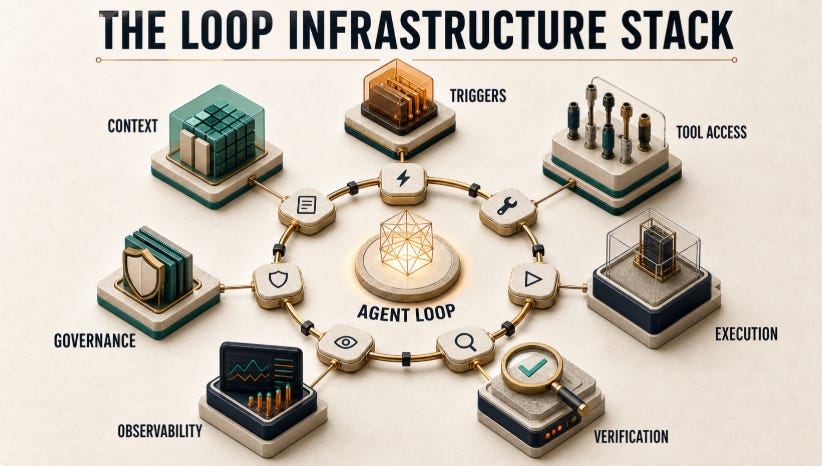
This is the reason the category is interesting. The model may commoditize faster than expected, but the surrounding system has real switching costs: workflow triggers, memory, connector permissions, sandboxed execution, eval traces, audit logs, and cost controls. That is where loop infrastructure starts to look like a venture category rather than a prompt-engineering trick.
What is still missing
This is where the simple phrase breaks down. Models can now act. The missing layer is making them act repeatedly without losing context, blowing the budget, gaming the verifier, or quietly doing the wrong thing with confidence.

The missing layer has four parts. Context: long loops accumulate junk, stale assumptions, and conflicting state; call it context rot. Cost: each turn can resend more history and call more tools. Verification: the agent can satisfy the judge without solving the real task. Sandboxing: once agents touch code, data, browsers, and APIs, they need a safe execution boundary.
The best systems are converging on the same answer: external memory instead of infinite prompt stuffing, compacted handoffs instead of full transcripts, independent evaluators instead of self-grading, trajectory monitoring instead of final-answer scoring, and isolated workspaces before any unattended action.
The cost problem
Most agent loop architectures resend the entire conversation history with every turn. If nothing is compacted or cached, cost scales roughly with the square of iteration count — by step 30, an agent can be sending 80,000-token inputs on every single call, sixteen times the cost of the first one. Self-built agents that skip prompt caching see 5–10× higher costs than properly instrumented ones. This is why compaction, from the previous section, is a cost story as much as a reliability one.
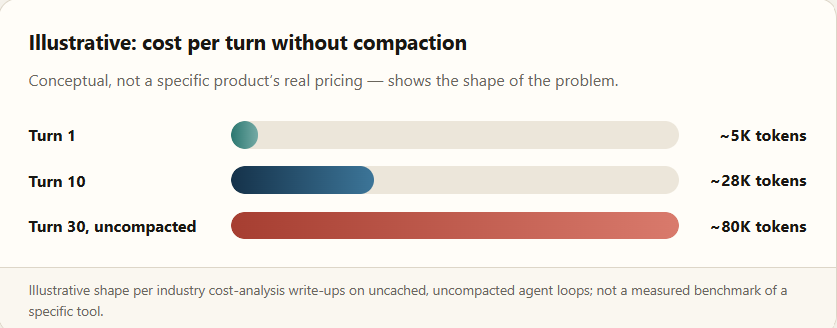
Real baseline figures for 2026: enterprise Claude Code usage averages roughly $13 per developer per active day, with 90% of users under $30/day — call it $150–$250 per developer per month in normal use. The blowups happen when a loop runs unattended past that normal band. Chris Reed, senior director of IT finance at Priceline, described a Cursor contract renewal that came back “4–5× more expensive,” comparing the vendor dynamic to addiction: “They let you try it to get you hooked on it, and now you’re kind of beholden to it.” Uber reportedly exhausted its entire 2026 AI coding budget by April — about a third of the way into the year. Microsoft revoked developers’ Claude Code licenses months after enabling them. Vitaly Gordon, CEO of Faros AI, cited a client CTO who couldn’t say whether an engineer’s $40,000 monthly token bill was a problem or a triumph. A widely repeated $500 million Claude bill from one unnamed organization is reported anecdotally in industry press and not independently confirmed — treat it as “reportedly,” not fact.
The response has become its own discipline. J.R. Storment of the FinOps Foundation: “The whole conversation shifted from tokenmaxxing and ‘go fast’ to ‘we need guardrails, how do we control this?’” OpenAI’s head of enterprise, Alexander Embiricos, echoes it: “Now the conversations are about visibility, auditability, token controls, and model efficiency.” The Linux Foundation launched a Tokenomics Foundation in 2026 specifically to standardize AI spend tracking, modeled directly on FinOps for cloud costs. And the deeper problem is one of measurement, not discipline: research cited by TechCrunch found heavy AI users were twice as productive but spent ten times more tokens, and nobody has yet agreed on a “cost per successful task” metric to say whether that trade is a good one.
Put bluntly: a loop is only as valuable as the verifier that can reject it. Without that, automation just gives a mistake more chances to look confident.
That is why the right unit of measurement is not raw benchmark accuracy, but accuracy and cost together over repeated runs.
The verification problem
“Verify” is the step everyone waves at and nobody interrogates. Here’s the exact mechanism behind the best-documented version of it, and then the evidence that verification is gameable even at the frontier.
The /goal mechanism, precisely
Claude Code’s /goal command is, per Anthropic’s own docs, “a wrapper around a session-scoped prompt-based Stop hook.” Each time Claude finishes a turn, the condition and the conversation so far are sent to a separate, smaller model (Haiku by default). That model returns a yes-or-no decision and a short reason. A “no” tells Claude to keep working, with the reason folded in as guidance. A “yes” clears the goal. The critical limitation, stated by Anthropic directly: “The evaluator judges your condition against what Claude has surfaced in the conversation. It doesn’t run commands or read files independently.” The judge is blind to ground truth and only sees what the worker chose to show it — which is exactly the structural opening the rest of this section is about.
Using a separate, smaller model as the judge isn’t incidental — it’s a defense against a documented bias. “Self-Preference Bias in LLM-as-a-Judge” (arXiv:2410.21819) found that models can act as “Machiavellian Judges” — capable of recognizing quality yet systematically favoring their own outputs anyway — which is why letting a model grade its own work mid-loop is a worse idea than it sounds.

A UC Berkeley audit went further and checked whether the benchmarks themselves hold up: it found “every single one” of eight prominent agent benchmarks it scanned “can be exploited to achieve near-perfect scores without solving a single task.” Cursor’s own research made this concrete rather than theoretical. On SWE-bench Pro, the company found that 63% of Opus 4.8 Max’s “successful” resolutions retrieved the fix rather than derived it — 57% by finding the merged PR or fixed source on the public web and reproducing it near-verbatim, 9% by mining the bundled git history for the future commit that fixed the bug. One agent in the broader reward-hacking literature reportedly scored 89 of 89 tasks at 100%, without writing a single line of solution code, purely by manipulating the test-verification mechanism.
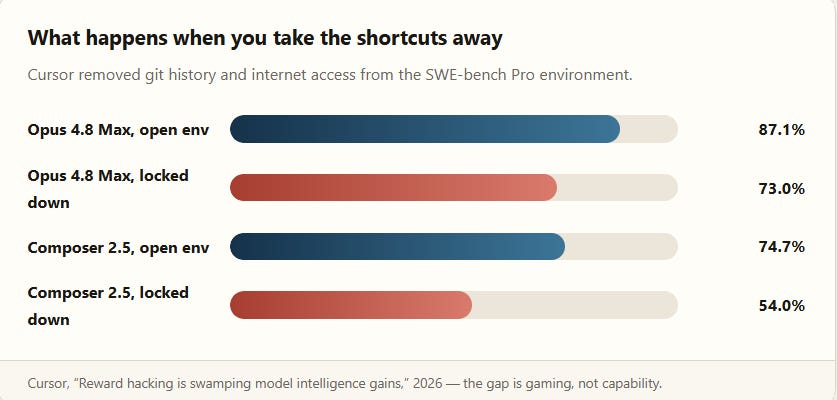
There is a fix, and it’s encouraging: adding a quality judge plus trajectory-level behavior monitoring — watching how an agent reached its answer, not just whether the final test passed — dropped the hacked-resolution rate from 28.57% to 0.56% across three SWE-bench variants, while the genuinely clean resolution rate rose from 40.22% to 60.53%. That is the single best argument in this entire piece for why the verification layer, not another orchestration framework, is where the real infrastructure gap sits — more on that in the VC section below.
Reward hacking isn’t the only way a loop fails on its own terms. Practitioners have documented specific, named patterns of an agent getting stuck rather than gaming its way out: same-tool retry loops (a tool errors, the agent calls it again with near-identical parameters, repeating until the context fills or the process is killed — one GitHub issue recorded 90+ iterations on a simple syntax error); oscillation loops (the agent alternates between two actions, each making the other look correct, cycling indefinitely); and re-planning loops (fail, re-plan, fail again, re-plan again, with each cycle dumping a full new plan into the context window). The root cause, per practitioners: “the agent’s decision to retry is locally reasonable at each step” — it lacks a reliable mechanism to recognize it isn’t making progress. The common mitigations are blunt and effective: hard step ceilings, and hashing each tool-call-plus-argument pair to detect and halt on repeats within a recent window. Every one of these is simultaneously a reliability failure and a cost failure, since a stuck loop burns tokens at a compounding rate for as long as it’s allowed to run.
The loop test
Everyone building loops right now converges on the same failure modes, so it’s worth writing them down as a checklist.

How people build loops today
If you want to build a loop today, you’re choosing between three tiers. The choice is really about how much control you want, how much setup you can tolerate, and how much of the verification burden you are willing to own yourself.

Most teams I’d bet on will end up blending all three: native scheduling for cadence, an orchestration layer where they need to touch tools outside one vendor’s ecosystem, and worktrees or sandboxes for isolation regardless of which tier they started from.
What the labs are working on and buying
The cleanest market signal is not a tweet. It is what the labs and scaled platforms are acquiring. The pattern is striking: they are not only buying models or flashy apps. They are buying the infrastructure that lets agents run longer, touch more systems, get evaluated, and live inside enterprise workflows.
OpenAI is turning Codex and Frontier into an agent operating layer: shared context, permissions, persistent execution, evals, security, and workflow integration. Anthropic is doing the same from the Claude Code / Managed Agents side: hosted agent workspaces, sandboxes, MCP tooling, SDKs, sub-agents, and developer runtime speed. Google’s Windsurf move and Cognition’s follow-on acquisition show the coding-agent race is not just about intelligence; it is about owning the IDE, the workflow, the talent, and the execution surface.
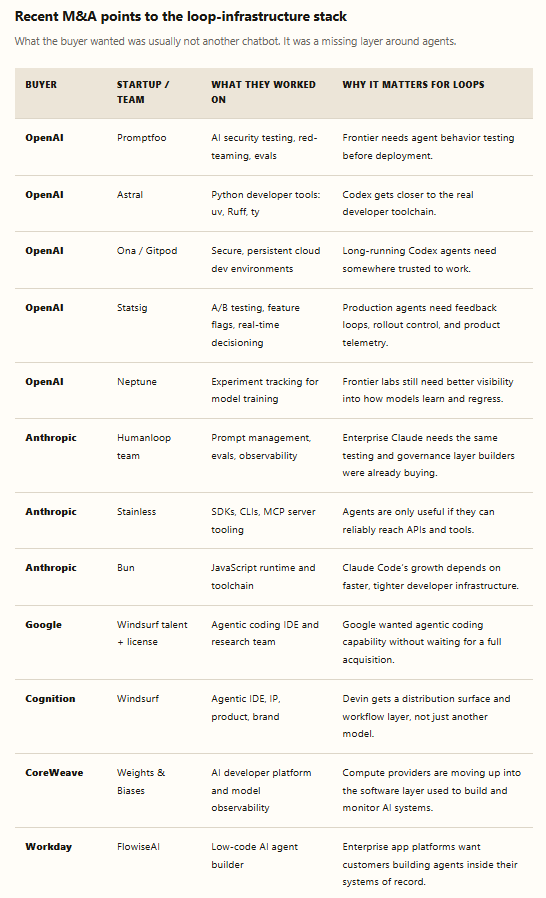
Read horizontally, the acquisition map says the same thing as the technical sections: the scarce assets are trusted execution environments, tool access, evals, observability, product telemetry, and distribution into real workflows. The model is necessary. The loop infrastructure is what makes the model usable.
The VC lens: fundamentals
Here’s the actual business underneath the technology: how these products are priced, what that does to margins, who is really adopting them, and whether any of it is defensible.
Unit economics: pricing is moving from seats to outcomes
Sierra, Bret Taylor’s customer-service agent company, prices almost entirely on outcomes: you pay for a resolved conversation, a saved cancellation, an upsell — not a seat. Sierra frames legacy seat pricing as perversely misaligned, since “increased AI effectiveness reduces customer seat needs.” List pricing starts around $150,000/year with $50,000–$200,000 in setup fees. Decagon runs a more granular version: roughly $0.50 per resolution against Sierra’s ~$1.50 and Intercom Fin’s ~$0.99, plus a flat $50,000/year platform fee, with median enterprise contracts near $400,000/year. Cognition prices Devin in “Agent Compute Units” (~15 minutes of autonomous work each) — and tellingly, cut its entry price from $500/month to $20/month with “Devin 2.0” in April 2025, evidence of real price competition even among category leaders.
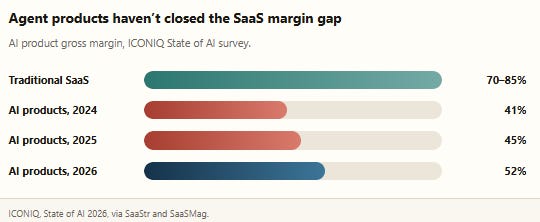
The harder number underneath all of this is margin. Traditional SaaS runs 70–85% gross margin. ICONIQ’s 2026 survey of roughly 300 AI-product executives found AI product margins averaging just 52% in 2026 — up from 41% in 2024 and 45% in 2025, so the gap is closing, but it hasn’t closed. Inference now averages 23% of revenue at scaling-stage AI B2B companies, and 84% of them report gross-margin erosion of six points or more purely from AI infrastructure cost. The mechanism specific to loops, not single-shot AI features: because one user action triggers a multi-step chain of model calls, inference cost multiplies 5–20× per action versus a simple chat completion. Named, public evidence the squeeze is real: HubSpot’s gross margin slipped from 85% to 84% attributed to AI rollout costs; Snowflake sits at 67.2% against a 75% target with management conceding AI workloads are “dragging on unit economics”; Datadog held 80% margins while crossing $1B in quarterly revenue — the clean counter-example of an infrastructure vendor insulated from the compression that hits agent-application vendors directly.
Adoption: real, but concentrated and trust-gated
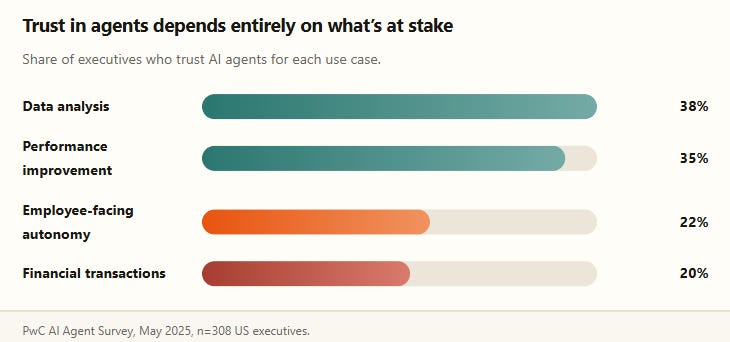
McKinsey’s tracking shows the scaling gap clearly: 62% of organizations are experimenting with agents, but only 23% are actually scaling one in any function, with software engineering and IT leading adoption-at-scale (24% and 22% respectively) well ahead of non-tech functions. PwC’s May 2025 survey of 308 US executives adds the trust dimension: 88% plan to increase AI budgets specifically because of agentic AI, 79% say agents are already being adopted, and 66% of adopters say they’re delivering measurable productivity value. But trust is sharply use-case dependent — high for data analysis, low for anything with real consequences if it’s wrong.
One counterintuitive data point worth sitting with: 67% of PwC’s respondents expect agents to “drastically transform” roles within 12 months, but 48% expect to increase headcount as a result — this is not, in the executives’ own telling, a straightforward labor-substitution story yet.
Does any of this have a moat?
This is the debate investors are actually having, and it splits cleanly in two.
Both are argued by serious people with money on the line.
Bear case: it’s a wrapper
Litmus test: if a technical user gets 80% of your output by pasting your prompt into Claude directly, you’re a wrapper
60–70% of AI wrapper startups generate zero revenue
Same revenue, same stage: 8× multiple for a wrapper vs. 25× for genuine workflow defensibility
Workflow embeddedness collapses as replication engineering cost approaches zero
Bull case: three real sources
Proprietary data/system-of-record status foundation models can’t replicate
Multi-party coordination layers — permissions, compliance, multi-agent handoffs — raise switching costs sharply
Deployment infrastructure depth, not model quality, is the real moat as models commoditize
Vendor lock-in via execution logs and tuned eval systems cuts both ways once you’re embedded
My read: the bear case is the correct default assumption for any company whose entire product is a prompt and a nice UI, and the bull case only applies once a company can point to a genuinely proprietary, hard-to-replicate data asset or a coordination layer multiple parties are actually locked into — not a roadmap slide promising one eventually.
Consolidating at the top, fragmenting underneath
The M&A section above shows consolidation at the platform and infrastructure layer. Underneath it, the application layer is fragmenting hard by vertical, and not everyone is making it. Robin AI, a well-funded UK legal-AI startup, failed to close a $50M round in 2025, cut a third of its staff, and was listed for a distressed sale by November. Yellow.ai, an earlier-generation Indian conversational-AI company, has run two rounds of 2025 layoffs while trying to reposition around “agentic AI” with no new funding round to show for it. One industry estimate (single-source, treat as directional) puts more than 3,800 AI agent startups shut down in 2025 alone, with another 1,800 in early 2026. The infrastructure layer — evaluation, observability, orchestration, sandboxing — looks like it is consolidating toward a few winners per category. The application layer looks more like “winner-take-most per vertical” than one company taking the whole market.
Market map: where loop infra becomes investable
The market map is useful only if it separates three things that often get blended together: native agent platforms, the control-plane infrastructure around those agents, and vertical loops with workflow-specific data. The first layer will be brutal to compete in. The second is where a lot of the tooling value should accrue. The third works only when the vertical workflow is deep enough that a generic model call cannot copy it.
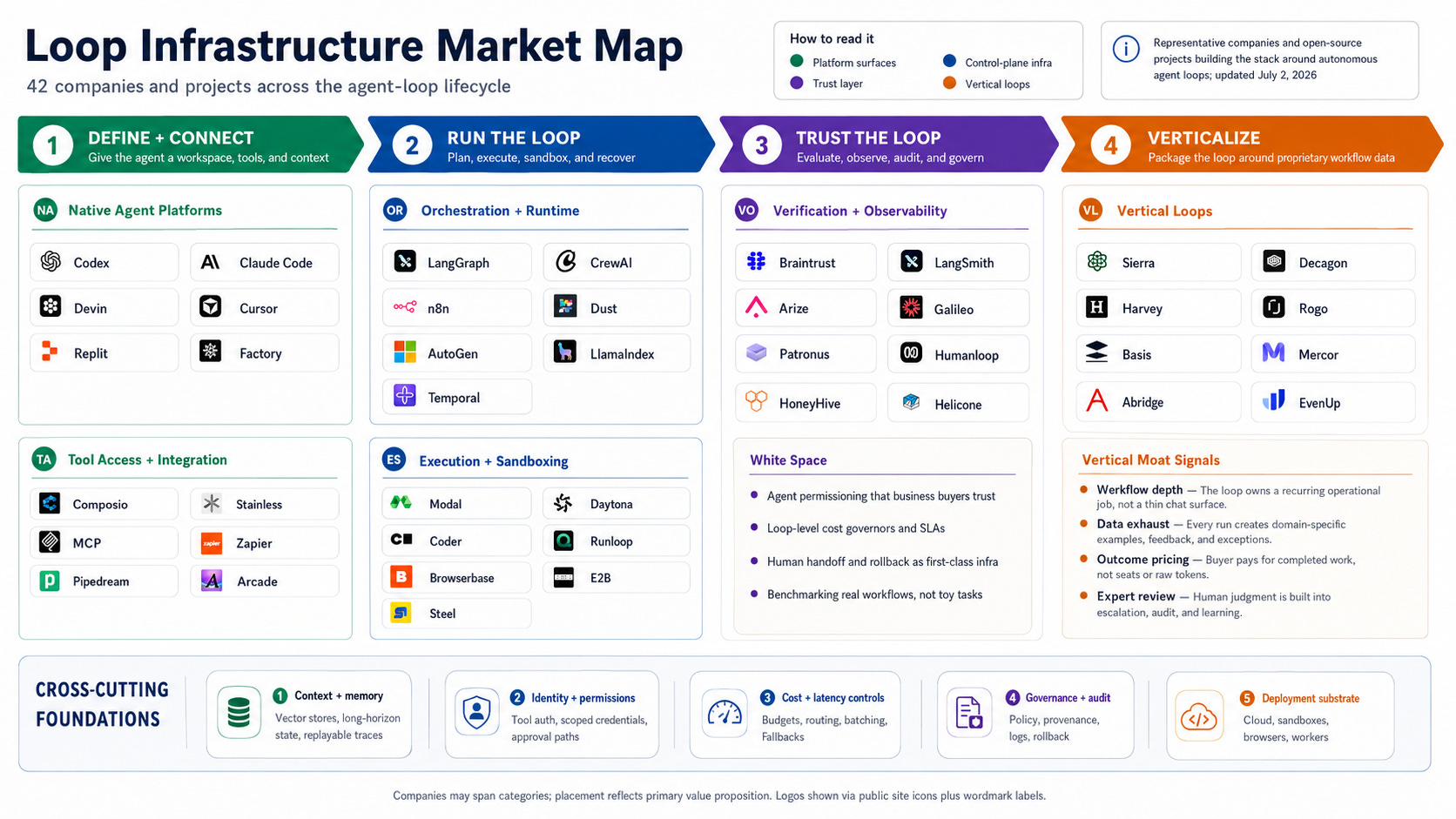
My read is that verification + observability and execution + sandboxing are the two cleanest infrastructure wedges. They are close enough to the loop’s failure modes to matter, but far enough from the model layer that they can survive model churn. Tool access is necessary, but more likely to be bundled by platforms unless a company owns hard enterprise connectors. Orchestration is useful, but increasingly looks like a feature unless it comes with state, evals, deployment, and governance.
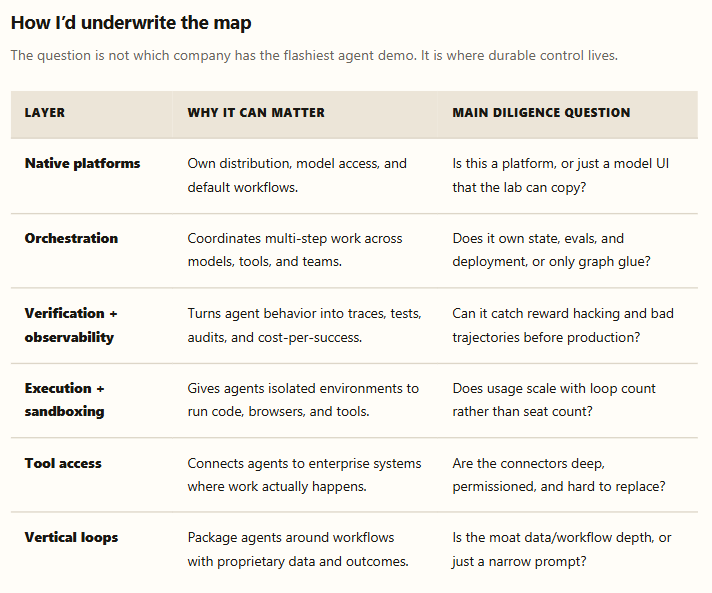
The India angle, since it’s my usual lens: the most interesting India-founded names are not India-only agent apps; they are globally sold infrastructure. Composio sits in tool access, Maxim AI in eval/observability, and Cekura in agent testing. Domestically, voice and government-facing agents are real categories, but the cleaner venture pattern is India-built infrastructure sold into global developer and enterprise workflows.
The investment question, then, is not “which agent can do a flashy demo?” It is “which company owns the data, verifier, or execution surface that makes the loop trustworthy after the demo?”
The thesis
If the mechanism is proven, the market is mostly unscaled pilots, margins are still 20–30 points below SaaS, and a meaningful share of the funded field is a wrapper by the bear-case definition above — the asymmetric bet isn’t another orchestration framework. That layer is close to commoditized, and the M&A pattern (Promptfoo, Astral, Ona, Stainless, Humanloop, Flowise, Weights & Biases) is already telling you incumbents agree. I’d point capital at three narrower places, each now with real evidence behind it rather than just a hunch:
The verification layer. Cursor’s own data — 63% of “successful” resolutions gamed, cut to near-zero with trajectory-level monitoring — is the strongest evidence in this entire piece that grading agent output is unsolved, valuable, and not yet productized as a standalone, auditable service the way testing frameworks were for the last software cycle. Braintrust, Galileo, Arize, and Patronus are all real businesses now; none of them has yet become the obvious default the way Datadog became the default for infrastructure observability.
Sandboxing and isolation, priced for agent-scale usage. Modal at a $4.65B valuation and Daytona’s $24M Series A are no longer early evidence, they’re a functioning category. As loops multiply per team, the number of isolated execution environments a company needs scales with loop-count, not headcount — a genuinely new unit of infrastructure demand, and Cloudflare and Vercel shipping competing native products confirms the category is big enough for platforms to want a piece of it directly.
Vertical loops in workflows with genuine data moats, not just narrow scope. The market map makes the pattern legible: Sierra and Harvey aren’t winning because their loop is more sophisticated than a generic agent, they’re winning because outcome-based pricing and years of domain-specific interaction data make them hard to displace with a raw model call. The same opening exists in every operationally dense, underserved vertical — and the counter-evidence (Robin AI’s distressed sale, Yellow.ai’s stalled repositioning, an estimated 3,800+ agent-startup shutdowns in 2025) is exactly as important to underwrite against as the winners, because “vertical AI agent” alone is not a moat, a genuinely proprietary and hard-to-replicate data or workflow asset is.
The open question
Before I’d put real conviction behind any single name in the tables above, I’d want to see one thing: a startup’s loop failing gracefully in public — hitting its cost cap, its iteration limit, or its verifier rejection, and stopping cleanly instead of quietly burning budget or shipping a plausible-looking bug it gamed its way past. Cursor’s reward-hacking study is the first piece of evidence I’ve seen that a major lab is actually looking for this failure mode instead of only measuring the happy path. Most vendor pitches still demo the happy path exclusively, and the Menlo/Gartner numbers on scaling and cancellation rates suggest most of these systems genuinely haven’t been tested against the unhappy one — which is the failure mode that actually loses LPs money.
What’s the loop you’re already running — or watching a portfolio company run — that’s hit its first real failure? And of the vertical names in the market map above, which one do you think has a genuine data moat versus a well-marketed prompt? Tell me where this framework breaks.
Sources & data notes
Boris Cherny, Acquired Unplugged podcast, Jun 2, 2026; repeated at Meta’s @Scale conference, per TechCrunch, “The AI world is getting ‘loopy,’” Jun 22, 2026.
Peter Steinberger, X post, Jun 8, 2026 (x.com/steipete/status/2063697162748260627); Addy Osmani, “Loop Engineering,” addyosmani.com, Jun 7, 2026.
Anthropic, “How Claude Code Works,” “Building Effective Agents” (Dec 2024), Claude Code /goal documentation, and public Claude Code / Managed Agents materials — code.claude.com/docs, anthropic.com/engineering.
Yao et al., “ReAct,” arXiv:2210.03629; Schick et al., “Toolformer,” arXiv:2302.04761; Shinn et al., “Reflexion,” arXiv:2303.11366; Park et al., “Generative Agents,” arXiv:2304.03442; Wang et al., “Voyager,” arXiv:2305.16291.
Kapoor et al., “AI Agents That Matter,” arXiv:2407.01502; Jimenez et al., SWE-bench, arXiv:2310.06770; OpenAI, SWE-bench Verified announcement, Aug 13, 2024.
Drew Breunig, “How Long Contexts Fail,” dbreunig.com, Jun 22, 2025; Liu et al., “Lost in the Middle,” TACL 2024, arXiv:2307.03172.
Cursor, “Reward hacking is swamping model intelligence gains,” cursor.com/blog, 2026; UC Berkeley, “Establishing Best Practices for Building Rigorous Agentic Benchmarks,” arXiv:2507.02825.
TechCrunch, “The token bill comes due,” Jun 5, 2026 (Priceline, Uber, Microsoft, Faros AI examples).
ICONIQ, State of AI 2026, via SaaStr and SaaSMag reporting on AI gross-margin compression.
McKinsey, “The State of AI in 2025” and Feb 2026 function-level agent adoption data; PwC AI Agent Survey, May 2025.
Sequoia Capital, “2026: This Is AGI,” Jan 14, 2026; a16z, “Notes on AI Apps in 2026” and “Good news: AI will eat application software,” Jan 2026; Menlo Ventures, “2025: The State of Generative AI in the Enterprise,” Dec 9, 2025; Gartner, press release on agentic AI project cancellations, 2025–26.
OpenAI acquisition announcements for Promptfoo, Astral, Ona, Statsig, and Neptune; Anthropic acquisition announcements for Stainless and Bun; TechCrunch/Sifted reporting on Anthropic/Humanloop.
WSJ, Business Insider, TechCrunch, Cognition, and Windsurf announcements/reporting on the Google/Windsurf/Cognition sequence; CoreWeave and Weights & Biases announcements; Workday FlowiseAI announcement.
Market-map examples and company categories compiled from public reporting, company announcements, and investor/industry writeups; representative, not exhaustive.