The Inference Market Map
Inside the inference serving layer — who runs the tokens, where the margin accrues, and what is actually contested.

NVIDIA cleared $75.2 billion in datacenter revenue last quarter at a 74.9% gross margin. Anthropic’s API run-rate hit $44 billion in May, up from $30 billion a month earlier. Cerebras IPO’d at $56 billion and traded to nearly $70 billion on day one. Fireworks is reportedly in talks at $15 billion. Baseten at $11 billion. fal.ai at $8 billion with $400 million of ARR. Vapi went from zero to a $500 million valuation in eighteen months after Amazon Ring picked it over forty competitors.
The numbers come from very different companies in very different sub-segments. They are all describing the same thing: the layer of the AI stack that turns a model’s output into a token in a customer’s response. Inference serving. That is the layer this memo is about.
Inference is now where the money in AI flows. By the end of this year, somewhere around two-thirds of AI compute spend will be inference, up from roughly one-third in 2023. Training gets the headlines; inference is the recurring revenue. The companies that get this layer right will compound for the next decade.
What follows is my best attempt at a current map. About eighty named companies organized into four horizontal sub-layers plus a column of modality verticals. Funding figures and ARR through late May. A take, layer by layer, on where margin actually accrues.
The stack
There is no agreed-on map of how inference serving is organized. Here is mine.
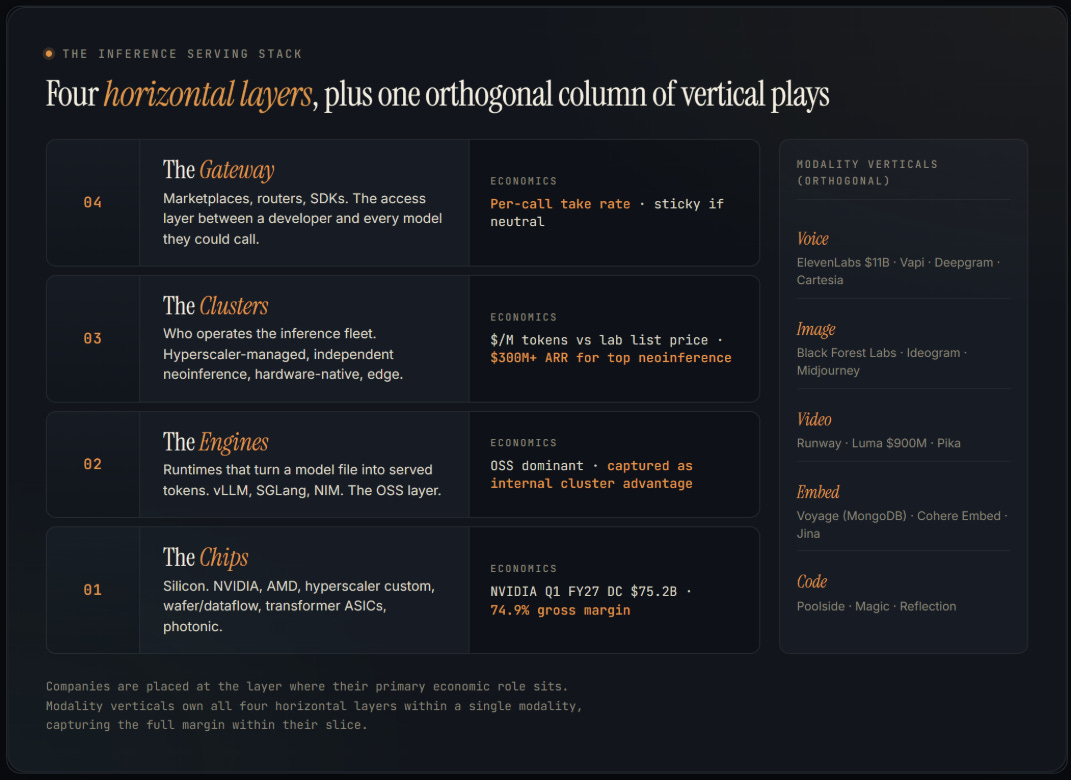
The Chips at the bottom are what hardware actually runs the inference. The Engines are the open-source runtimes (vLLM, SGLang, NIM) that turn a model file into served tokens. The Clusters are the companies that operate the fleets at scale — AWS Bedrock at one extreme, Fireworks and Cerebras Inference at the other. The Gateway is the access layer developers actually call through — OpenRouter, Vercel AI Gateway, lab SDKs.
Running alongside all of that, the modality verticals: companies that own the chip choice, engine, cluster, and API surface within one slice of the world. ElevenLabs in voice. Black Forest Labs in image. Runway in video. Voyage in embeddings (now part of MongoDB). Poolside in code. Each of these is its own stack, vertically integrated, capturing the full margin within its modality.
The next figure is the map of who actually sits where.
The map
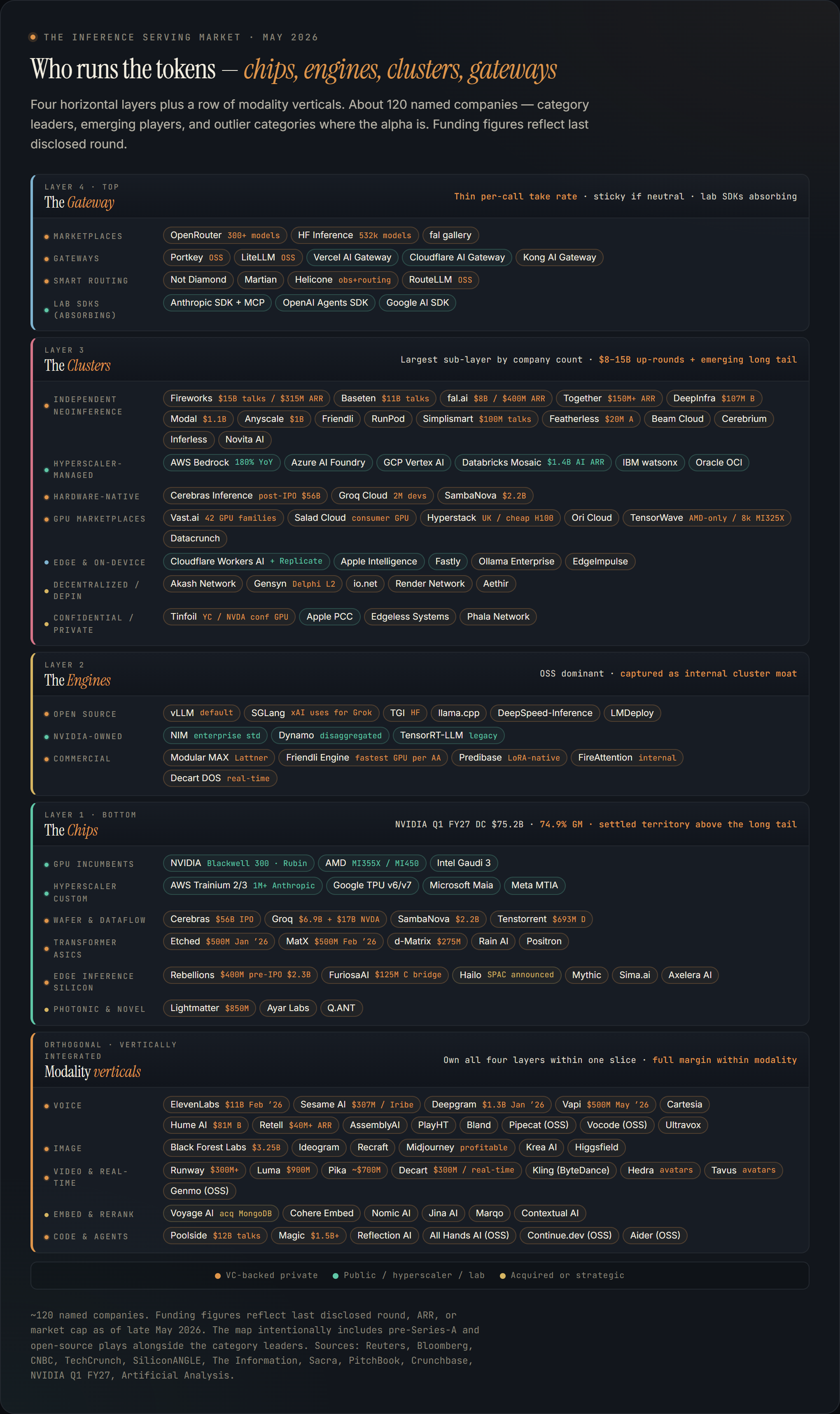
The Chips
This layer is the most obvious story in AI infrastructure, so I’ll be brief. NVIDIA cleared $75.2 billion in datacenter revenue last quarter at 74.9% overall gross margin. AMD has become a credible second source with the MI355X and MI450, helped by the OpenAI six-gigawatt commitment. Hyperscaler custom silicon (Trainium, TPU, Maia, MTIA) is a margin lever inside each hyperscaler, not an external market. Cerebras just IPO’d at $56 billion. Groq took $17 billion from NVIDIA in a licensing deal. SambaNova reset to $2.2 billion after a tough year.
The interesting bets on the silicon board are less about NVIDIA vs. challengers and more about whether two specific outliers work. Transformer-specific ASICs — Etched ($500M) and MatX ($500M, led by Jane Street and Situational Awareness) — are the cleanest binary in the stack. If transformers stay the dominant architecture through 2028, dedicated silicon outperforms general-purpose by an order of magnitude. If they don’t, both go to zero. The South Korean edge-inference cluster (Rebellions at $400M pre-IPO, FuriosaAI at $125M, Hailo going public via SPAC) is the quieter story: real money chasing inference-specific designs at the edge, where NVIDIA’s networking lock-in doesn’t apply the same way.
The take: chips is settled territory at the top and interesting at the edges. NVIDIA wins the obvious moat. The asymmetric bets sit in transformer ASICs and edge inference silicon, not in the wafer-scale plays competing with NVIDIA at the datacenter scale.
The Engines
The engine is the layer between a model file and a stream of tokens. It is where research papers like PagedAttention, continuous batching, speculative decoding, and FP8 quantization turn into running code. And it is where the open-source layer has won so completely that there is almost no margin left for pure-play vendors.
vLLM, originally out of UC Berkeley, is the default. SGLang is the faster alternative for certain configurations — xAI uses SGLang to serve Grok. NVIDIA TensorRT-LLM was the previous answer; NVIDIA is transitioning to Dynamo, a newer disaggregated serving framework that separates prefill from decode. NIM, NVIDIA’s containerized inference microservices, has become the enterprise standard way to ship an LLM in 2026. TGI from Hugging Face. llama.cpp for CPU and edge. DeepSpeed-Inference for the more research-oriented workloads. All open source.
The commercial layer above OSS is small and absorbing fast. Modular MAX is Chris Lattner’s commercial play. Friendli Engine is Korean and currently ranked the fastest GPU-based serving provider by Artificial Analysis. Predibase specializes in serving LoRA fine-tunes. Each occupies a defensible niche, but none of them is a venture-scale standalone business.
The cleanest signal that engines don’t capture margin alone is that the most successful proprietary engines aren’t sold as products. Fireworks’ FireAttention is internal. Together’s TGI fork is internal. Baseten’s optimization stack is internal. Each is a competitive moat for the cluster it powers, not a standalone product line.
The take: this layer has already settled. OSS dominates. Real margin gets captured one layer down (NVIDIA with NIM) or one layer up (clusters with their internal optimizations). I don’t see a pure-play engine vendor reaching $100M of ARR.
The Clusters
This is where the dollars are. And where the four most recent up-rounds happened.
Together at $150M+ ARR. Fireworks at $315M ARR and reportedly in talks at $15 billion, four times its $4 billion Series C valuation from seven months earlier. Baseten in talks at $11 billion in May, up from $5 billion in January. fal.ai at $400M ARR and in talks at $8 billion in March. DeepInfra closed $107 million Series B in May with NVIDIA and Samsung Next participating, and is now processing close to five trillion tokens per week. All of this in five months.
The cluster layer breaks into four very different business models, and the difference matters more than the funding numbers do.
Hyperscaler-managed (AWS Bedrock, Azure AI Foundry, Google Vertex AI, Databricks Mosaic AI) wins where customer data already lives. AWS Bedrock is growing 180% year over year in adoption. Over 100,000 enterprises run Claude on Bedrock as of April 2026. The hyperscalers don’t need to win on price or speed; they win on the customer not wanting to move their data out of the perimeter they already trust.
Independent neoinference (Together, Fireworks, Baseten, Modal, DeepInfra, fal.ai, Anyscale, RunPod, Friendli) is the most contested sub-layer. Open-weight serving on commodity GPUs at competitive cost-per-token. Margin depends on whether open-weight share of inference keeps growing. It is. Whether $15B for Fireworks is the right price is a separate question.
Hardware-native vertical (Cerebras Inference, Groq Cloud, SambaNova Cloud) is the only credible NVIDIA bypass at the cluster level. Own the chip, own the cluster, capture the full vertical margin. Limited to what your silicon can serve well — Cerebras for long-context flagship models, Groq for low-latency open-weight serving.
Edge serving (Cloudflare Workers AI, Apple Intelligence on-device, Fastly Compute@Edge) is small but growing fast. Cloudflare’s Q1 2026 revenue hit $640 million on +34% growth, with Workers AI billing driving the upside. The December 2025 acquisition of Replicate added a model marketplace on top of the edge cluster — the only player in this layer attempting all four horizontal positions at once.
The headline numbers belong to the top of the cluster layer. The more interesting question is what’s happening underneath them, because that’s where the next category-creating outcomes will come from. Featherless.ai closed a $20 million Series A from AMD Ventures and Airbus Ventures in April for serverless hosting of 30,000+ open-weight models — an order of magnitude more breadth than Together or Fireworks. TensorWave is the AMD-exclusive specialist, with the largest AMD GPU training cluster in North America (8,192 MI325X accelerators) and a clear thesis that AMD second-source becomes a real category. Vast.ai runs a decentralized GPU marketplace with 42 GPU model families. Simplismart in India is in talks for $20M led by NVIDIA at a $100M valuation. Below Featherless: Beam Cloud, Cerebrium, Inferless, Novita, Salad Cloud serving the long tail at $5–30M of disclosed funding each.
The take: clusters is where the VC dollars are landing right now, and where the next valuation reset will start. The top of the layer (Fireworks, Baseten, fal.ai) is priced for compounding; the bottom is where the asymmetric returns sit if you can pick which thesis-specific play (long-tail breadth, AMD specialization, regional focus, GPU marketplace) actually has structural advantage. Hardware-native vertical and hyperscaler-managed are the most durable sub-models. Independent neoinference will consolidate aggressively over the next 18 months — my best guess is two or three names at the top survive at scale, three or four emerging names break out, and the rest get acqui-hired or quietly fold.
The Gateway
The thinnest layer in the stack. Marketplaces (OpenRouter, Hugging Face Inference), gateways (Portkey, LiteLLM, Vercel AI Gateway, Cloudflare AI Gateway), smart routers (Not Diamond, Martian), observability-plus-routing (Helicone). Each one sits between a developer’s code and the inference endpoint of their choice.
The category exists because enterprises don’t standardize on one model. The current shape: most enterprises run AI across five or more surfaces — Anthropic direct, OpenAI direct, AWS Bedrock, Azure AI Foundry, Google Vertex, plus AI features in their data platform, dev tooling, CRM, and support stack. Someone has to manage that, log it, govern it, fall back when a provider has an outage. Gateway tools do.
But the take rate per call is thin and the moat is mostly switching cost. And here is the structural risk that decides the layer: the frontier labs are absorbing the function with their own SDKs. Claude SDK plus MCP. OpenAI Agents SDK. Google AI SDK. Each one increasingly assumes you call its parent lab’s models, with routing and orchestration logic embedded in the SDK itself.
Portkey’s response in March 2026 was to open-source the entire gateway under Apache 2.0. LiteLLM was OSS to begin with. The category is racing to commodify itself before the lab SDKs eat it.
The take: gateway is the most likely layer to consolidate or get absorbed in the next 18 months. The winners are the ones that become infrastructure rather than products. OpenRouter has the best position because it operates as a true marketplace with credit-based billing — the lab SDKs structurally cannot aggregate competitors’ models the way OpenRouter can. The OSS gateways (LiteLLM, Portkey) win as embedded primitives. Everyone else gets compressed.
Modality verticals
The other half of the inference serving story. Some companies don’t sit on a horizontal layer at all — they own all four (chip choice, engine, cluster, API) within one modality, and capture the full margin within their slice.
Voice has gone from $315 million of VC in 2022 to $2.1 billion in 2024 to multi-billion-dollar valuations in 2026. ElevenLabs raised $500 million Series D at $11 billion in February. Vapi raised $50 million Series B at $500 million in May after winning Amazon Ring over 40 competitors. Deepgram raised $130 million Series C at $1.3 billion in January. Cartesia is the latency leader. Hume is the empathy and emotion play. Retell hit $40M+ ARR with 300% quarter-over-quarter user growth. AssemblyAI, PlayHT, and Bland round out the field. This is the hottest sub-category in inference right now, and it is at the early stage of consolidation. ElevenLabs is priced as the winner; the rest disagree.
Image has been a category for two years now and has stabilized. Black Forest Labs ($3.25 billion in December 2025) is the open-weight standard. Ideogram and Recraft are the major paid challengers. Midjourney is profitable, private, and notably has never taken venture funding. The category is more stable than voice because the open-weight base (Flux) sets a price floor that everyone else respects.
Video is the fastest-moving. Runway, Luma ($900 million round), Pika, Kling (ByteDance). The cost curve is dropping faster than text — what cost roughly $1 per second to generate in 2024 is closer to $0.10 in 2026. Hollywood-grade output is the differentiator that’s actually worth paying for.
Embeddings consolidated first. MongoDB acquired Voyage AI in February 2025 for $220 million. Cohere has embed-v4 inside its $7 billion model business. Nomic ships open-source. Jina has multilingual long-context. The category was small enough that a horizontal infrastructure player (MongoDB) could roll up the leader. That pattern will repeat in other modalities.
Code is the most contested vertical. Poolside is in talks at $12 billion with $1 billion already committed, including $500 million to $1 billion from NVIDIA. Magic is targeting $1.5 billion-plus. Reflection AI is earlier-stage. But the more important move is that the application-layer leaders — Cursor at $50 billion in talks, Cognition at $25 billion — are increasingly running their own inference internally rather than buying from cluster providers. That is a sign the vertical-by-modality thesis extends up the stack into applications themselves.
The take: vertical integration is real in modalities where the demand profile is distinct (voice latency, video frame coherence, embedding semantics). Whether each modality consolidates to a single winner or stays a multi-player market is open. Voice and code look like they consolidate. Image and video look like they stay multi-player. Embeddings already consolidated — into an adjacent infrastructure vendor, which is a model I expect to repeat.
Underexplored corners
If you spent twenty minutes looking at the map above, you noticed that the obvious bets are now priced for compounding. Cerebras is public at $56 billion. Fireworks is in talks at $15 billion. ElevenLabs at $11 billion. Cursor at $50 billion. The headlines are fully claimed.
The interesting question, especially for venture investors entering today, is which underexplored corners of the inference stack become the next category-defining names. Four worth watching closely.
Confidential and private inference. Tinfoil is the cleanest pure-play: multi-GPU confidential computing on NVIDIA Hopper and Blackwell, hardware-enforced privacy, Red Hat partnership. Apple Private Cloud Compute exists at hyperscaler scale but isn’t available to other developers. Edgeless Systems and Phala Network occupy adjacent slices. The category exists because every regulated industry (healthcare, finance, defense, legal) needs a way to call frontier inference without sending data outside its trust boundary. Today there is essentially no neutral commercial answer. Whoever builds it first becomes infrastructure.
Decentralized / verifiable inference. Akash Network already runs a permissionless GPU marketplace with instant Llama and Stable Diffusion deployment. Gensyn launched Delphi on an Ethereum L2 in April with a Reproducible Execution Environment that produces cryptographic proofs of correct compute. io.net, Render, Aethir round out the DePIN side. The thesis is contested — crypto-infrastructure for AI compute has been promised for three years and mostly underdelivered — but the primitive (verifiable compute the user doesn’t have to trust) is genuinely useful, especially for agentic workloads that move money. Worth watching whether 2026 is the year it actually ships.
Real-time generative video. Decart closed $300 million in May from Radical Ventures, NVIDIA, Sequoia, Benchmark, Adobe Ventures, and Toyota Ventures for what it calls real-time world models — sub-30-millisecond generative video built on a proprietary optimization stack (DOS). Runway and Luma can’t reach this latency profile with batch generation. If real-time video opens a category (gaming, robotics simulation, AR), Decart sits alone in it. The bet is binary and big.
Long-tail open-weight serving. Featherless hosts 30,000-plus open models, an order of magnitude beyond Together or Fireworks. The economic question is whether depth-of-catalog matters more than speed-on-Llama for the next $100 million of cluster ARR. If you believe the open-weight long tail keeps fragmenting (as Hugging Face suggests it does), Featherless is a structurally different bet from the leaders. AMD Ventures led the Series A, which is its own signal about where AMD thinks the open-weight serving market goes.
Adjacent to all four: voice frameworks (Pipecat from Daily.co, Vocode, Ultravox) running as open-source plumbing under most production voice agents, and AMD-specialized clusters like TensorWave, where the bet is that AMD second-source becomes a real category over the next 24 months.
None of these are guaranteed. All of them are priced one or two orders of magnitude below the category leaders — which is exactly why they belong on a market map for investors, not just an industry roundup for incumbents.
Where margin lives

The scorecard above is what it actually feels like to be a company at each layer. The pattern that emerges is the one that holds across most large infrastructure markets: margin lives at the edges, and the middle is where the squeeze happens.
Chips at the bottom: high pricing power, high capex, low substitution risk for NVIDIA, multi-year time-to-resolution. Modality verticals at the top of their slices: meaningful pricing power, moderate capex, moderate substitution from open weights, two-to-three-year window before the leader is visible by name.
The middle layers each have their own story. Engines are the cleanest negative: OSS-dominant, hard to charge, already settled. Clusters are the most interesting because the recent up-rounds suggest investors believe the category compounds — but substitution risk is high and the time-to-resolution is short. Gateway is racing the lab SDKs and the next 18 months decide whether it survives as a venture category at all.
If I had to allocate venture dollars into this map today, I’d bias roughly 35% to chips and silicon-native vertical serving, 30% to modality verticals (especially voice and code), 20% to a small number of horizontal cluster names (Fireworks and Together, possibly Baseten if the premium-quality thesis holds), 10% to gateway plays biased toward OSS-distributable infrastructure (OpenRouter, LiteLLM), and 5% to engines, which mostly means betting on the people behind the open-source consortia rather than the consortia themselves.
Speed vs. cost
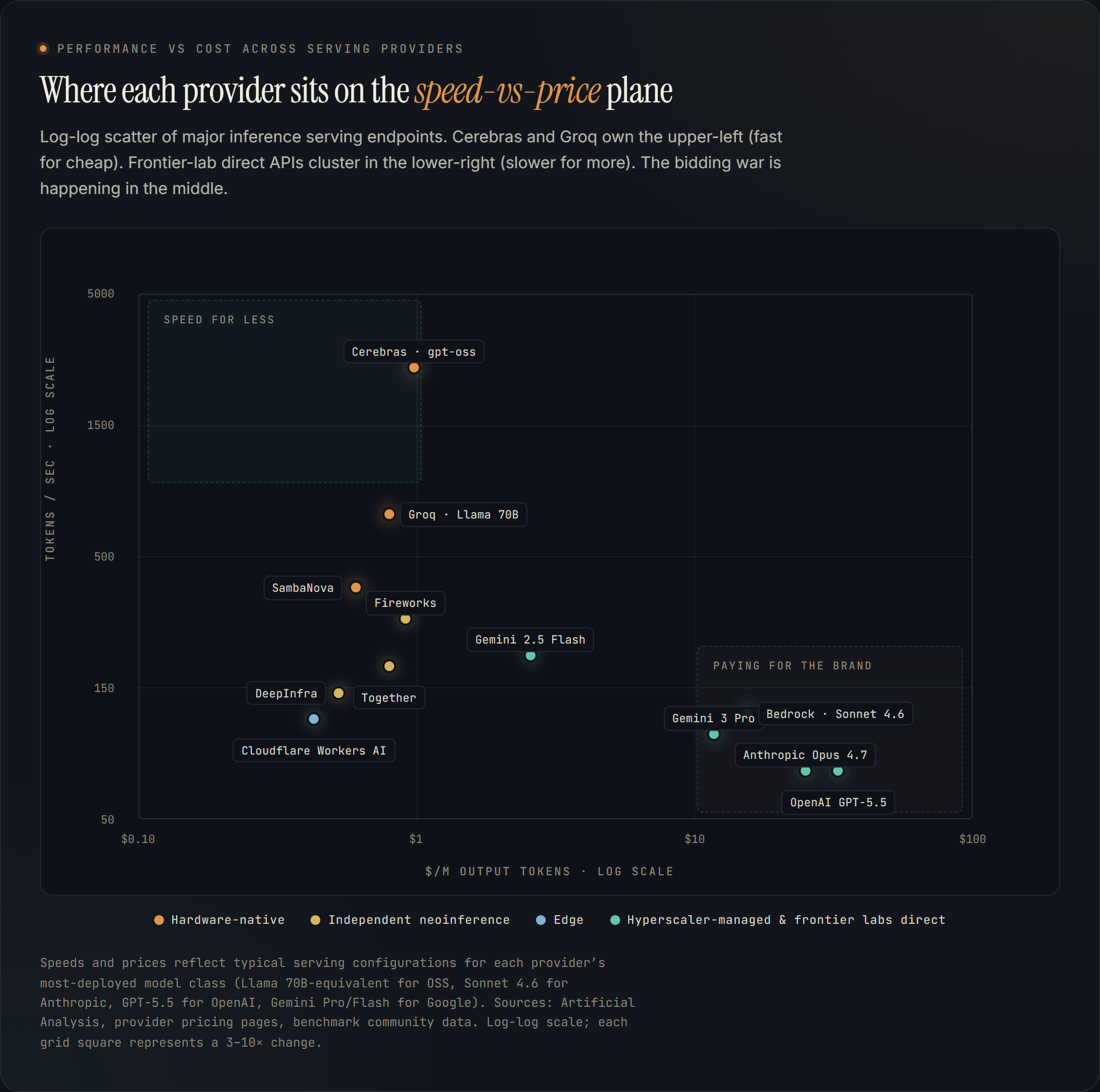
The chart above shows what each major serving endpoint actually delivers. Two patterns jump out.
First, the upper-left quadrant — fast for cheap — is mostly owned by hardware-native plays. Cerebras at 3,000 tokens per second on gpt-oss is in a class by itself. Groq at 750-plus tokens per second on Llama 70B is the closest competitor. SambaNova rounds out the trio. These speeds are inaccessible to GPU-based serving without paying premium prices.
Second, the lower-right — slower and more expensive — is where the frontier labs sell direct. GPT-5.5 and Claude Opus 4.7 deliver around 80 tokens per second at $25 to $30 per million output tokens. That is the price of brand, trust, and managed support, not raw performance. The same Sonnet 4.6 served on AWS Bedrock isn’t dramatically faster than calling Anthropic direct, because it’s the same model on the same hardware mediated through enterprise contracts.
The middle is the bidding war. Fireworks, Together, DeepInfra, Cloudflare Workers AI, Gemini 2.5 Flash all sit within roughly a 3× envelope on both axes. This is where price competition is most intense, where investors are paying the highest revenue multiples, and where the next eighteen months of consolidation will play out.
What I think happens
ree years and roughly $700 billion of committed compute. $109 billion of VC into AI infrastructure in 2025 alone. The headline names on the map are priced for compounding. By any normal standard, the obvious bets are made.
What’s actually interesting about inference serving is not which obvious bet wins. It’s that this is a market where capital is uncapped, demand is uncapped, and the bottleneck moves between layers faster than in any prior infrastructure cycle. Six months ago the binding constraint was H100 supply. Now it’s HBM and advanced packaging. In 2025 it was datacenter power. The layer that captures margin this quarter isn’t necessarily the layer that captures it next quarter. Most of the layer-winner predictions you’ll read this year — including some of the ones above — will look wrong by 2027.
So the question worth answering is the one I keep coming back to. Which positions in the stack are structurally impossible for OpenAI, Anthropic, and Google to take themselves, even if they wanted to?
I count three.
Confidential inference the customer can cryptographically verify, which the labs can’t credibly offer because they are the trust boundary. Edge and on-device serving at sub-30-millisecond latency, which they can’t reach without hardware they don’t own. And specialty silicon designed for inference workloads the labs are too generalist to optimize.
Those are the three positions where asymmetric upside actually lives. Not because they’re the biggest categories today — two of them barely exist as categories — but because the labs can’t replicate them by next quarter’s release, the way they can absorb gateway, agent SDK, or generic horizontal serving.
Sources
Cerebras IPO: TechCrunch; CNBC.
Fireworks AI: Bloomberg, $15B talks; Sacra for ARR.
Baseten: $11B talks; Sacra.
fal.ai: Sacra ($400M ARR).
Together AI: Tracxn.
DeepInfra: Series B announcement.
Modal: $87M Series B Sep 2025; PitchBook.
Groq + NVIDIA license: IntuitionLabs writeup.
SambaNova: Sacra.
MatX: TechCrunch.
Etched: Bloomberg.
ElevenLabs: Series D announcement.
Vapi: TechCrunch.
Deepgram: Deepgram.
Black Forest Labs: TechCrunch.
Luma Labs: $900M round (per industry reporting).
MongoDB / Voyage AI: MongoDB IR.
Cloudflare / Replicate acquisition: Cloudflare press, December 2025.
Poolside: Sacra.
NVIDIA Q1 FY27: NVIDIA IR.
Anthropic ARR May 2026: Bitget aggregating Anthropic disclosures.
Salesforce Agentforce ARR: Futurum Group / Salesforce.
Databricks: Databricks IR.
Performance benchmarks: Artificial Analysis.
VC market sizing: OECD AI VC report through 2025.